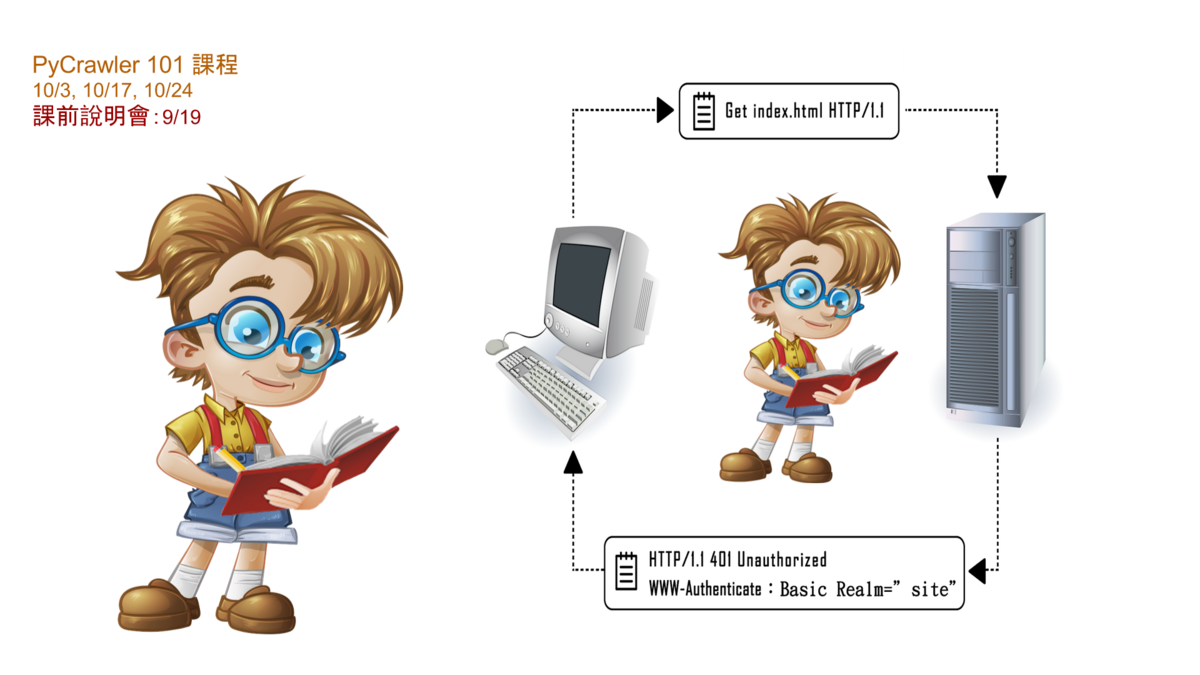
PyCrawler 101 課程
網路爬蟲會不會很難學?
「Crawler 101 ~ 102 系列」 是一門想幫助學員,能夠快速的從初階到精通的課程!
不論,你是新手蟲友,或是剛入門的蟲友 ...
我們都希望,這堂課可以帶給你不同層次的學習、挑戰、享受與成就感!
-
給還是初學者的你:
其實,網頁爬蟲沒有想像中的那麼困難,只要知道一些基本的網頁技術與觀念,就能在短時間內寫出第一隻爬蟲。多短呢?半天,你也能寫出爬蟲唷!一起來試試吧!
(如果不小心玩上癮的話,我們也曾經教過,初學者在一個月內就變得非常厲害的唷!)
-
給剛入門的爬蟲寫手的你:
相信,在爬行的路途上,你一定也遇過不少難纏的網站,面對日新月異的網站技術,想寫出攻無不利的爬蟲,你需要知道更多攻防戰法。讓身經百戰的爬蟲寫手,告訴你對付難纏網頁的秘訣!
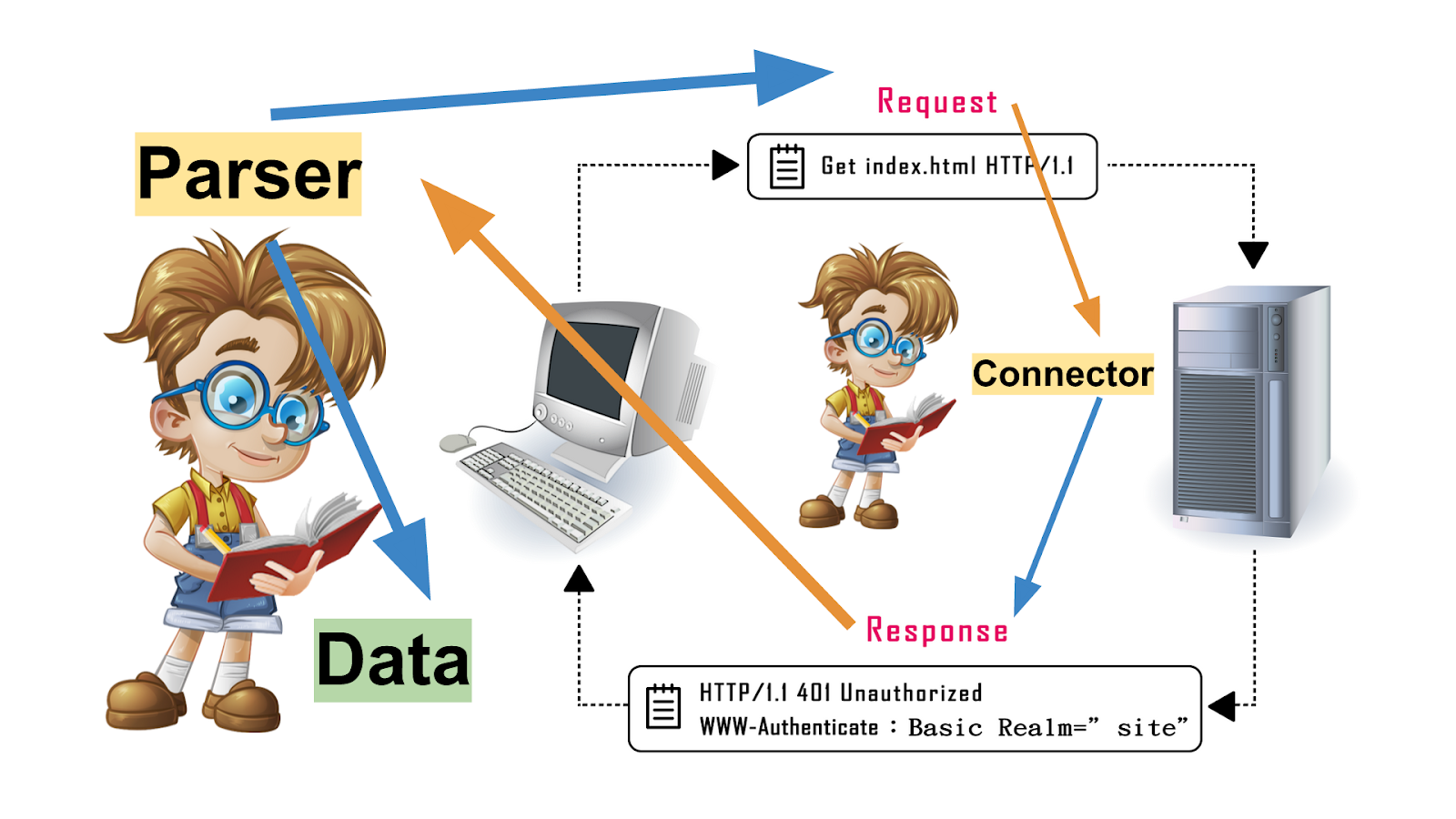
其實,網路爬蟲最難的部份 ... 是觀察!
不論,你是新手蟲友,或是甫入門的蟲友 ...
爬行時,如果遭遇到困難,大多數都來自觀察!而不是寫 code 或是實做!
因此,我們並不會像一般的網路爬蟲課一樣,僅僅教你如何使用某種語言的 code 來完成某些特定的爬行工作。
我們會從新手,就開始教你各種需要豐富經驗才能累積出來的觀察流程與觀察技巧!
並提供大量的練習機會,讓學員有機會可以大量練習這些技巧!
(為了這堂課,我們大約準備好了將近 70 各個種不同難度的網站,不同學習目標,可以隨時給大家練習與挑戰!)

一般來說,我們都希望站在資訊不對稱的一端 ...
以個人來說,你是否會想知道,最近的近三個月之中,有哪些朋友,常在你的 Facebook 上按讚與留言的呢?想要偷偷的知道一下,到底有哪些朋友在關注自己呢?
(當個自己的小小徵信社)
或是,你是否曾經使用 Facebook API 來抓取一些朋友或粉絲團的資料,想要抓取大量資料,但卻苦於 token 每兩個小時就會 expired 一次,無法自動更新呢?(覺得每次抓資料前,都要去 Graph Explorer 剪下貼上一次,很麻煩!)

面對著這個資訊量極大的年代!許多原本只能仰賴內部資料的商業決策,也開始利用大量的外部資料,更精準的定位與定義,各種市場與客群的問題。
例如,最近在美國出現的輿情炒股系統,就是利用 Twitter 上大量的使用者留言資料,來預測或投資股票市場!
這是個資料快速變化的世代 !
Amazon 的自動調價系統,可以在兩小時內自動對整體商品進行價格調整!
而身為一個資深股民,我們觀察到 DRam 和面板產業,其股價的變動往往是落後於終端市場的價格變動。 因此,監控 PCHome 和 Amazon 上的相關商品的價格資料,對於做相關的投資決策,是有非常大的幫助的!
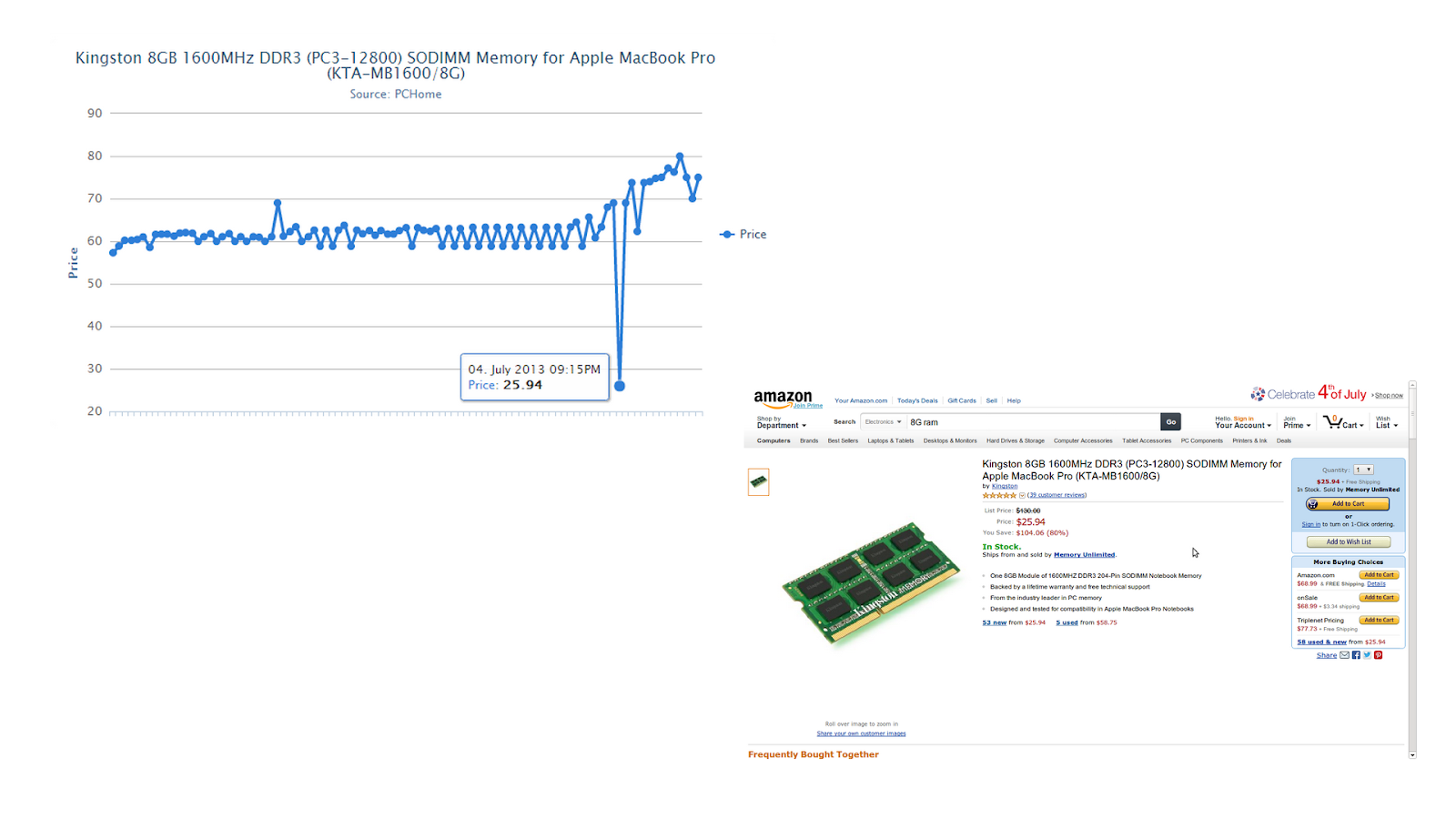
這是個可以快速,取得大量公開資料的世代 ...
隨著網路的崛起,人們也可以更快速的取得各種資料,發揮各種創意,做出許多原本要花很多人力,或是原本根本不可能做到的事情!
例如,你可以像 WhosCall 或 WhatsTheNumber 一樣,大量的取得各種電話資訊,來協助人們解決所遇到的問題。
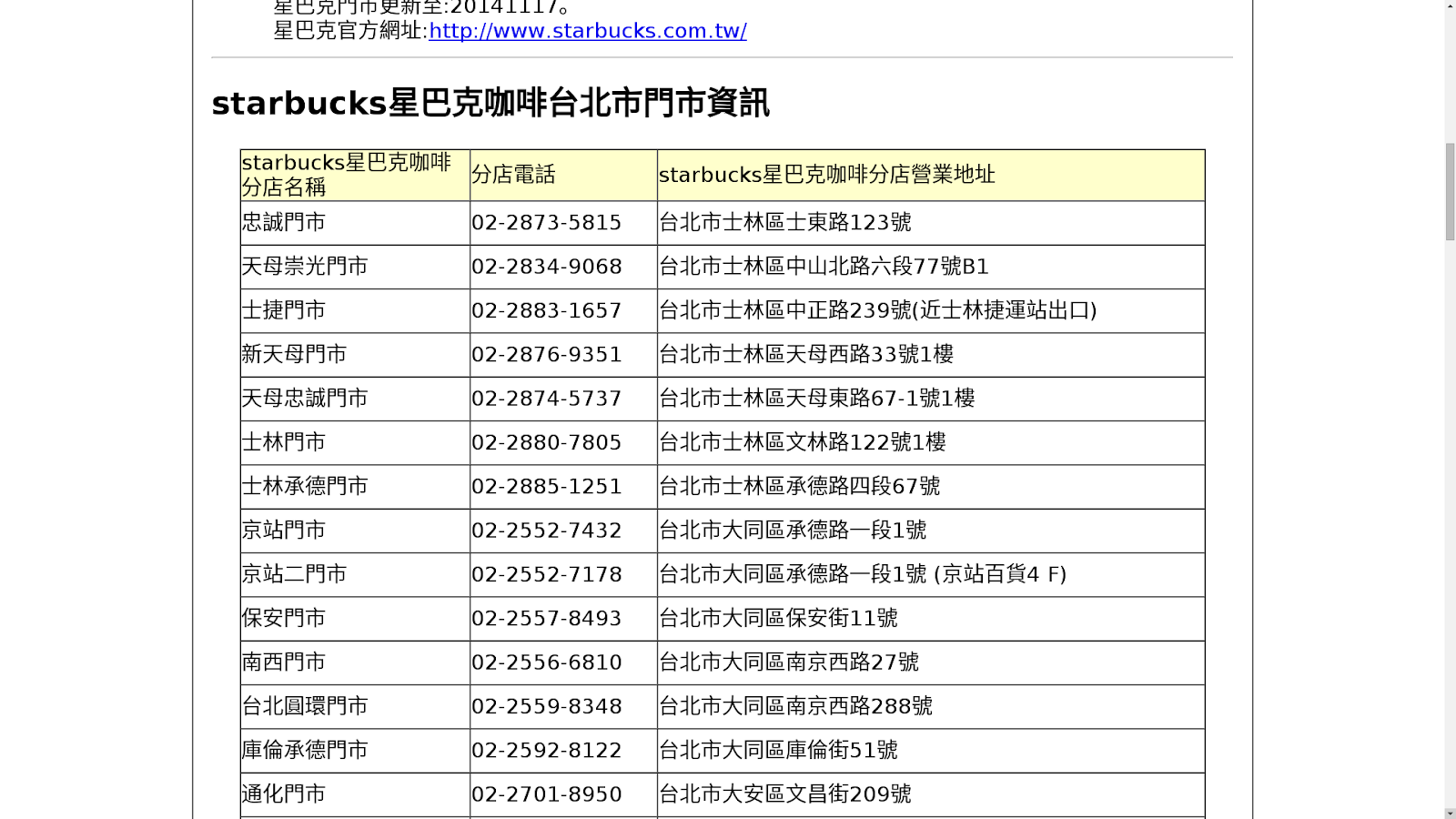
當然,如果你是個商業決策者,相信上面的地址資訊,也可能是,可以輔助您決策的重要資訊之一唷!
如何站在資訊不對稱的一端 ... ?
這部份的技術,大概可以分成兩大部份:
如何大量取得資料?
如何將資料轉成資訊?
由於,機器並不會自己學會東西,主要還是靠您提供的訓練資料來學習與建模。

所以,資料的來源是否有偏誤?是否完整?是否有大量關聯資訊?
都是非常非常重要的問題!
例如說,如果您只抓取八卦版,但是您想使用輿情分析來思考選情未來的發展,就是非常不明智的作法!少了對照組的資料,會讓所抽取出來的資訊,有大量的偏誤唷!
所以,一般來說,我們也會同時建議抓取政黑板的資料!
唯有大量蒐集完整的資料 ...
才能真正站在資訊不對稱的一端 ...
雖然,我們無法保證在有限的上課時間中,能講完以上所有的範例!
但是,可以保證的是,如果你把上課中提到的技巧都學會了,假以時日,上述的網站中的資料,都可以如探囊取物般的拿到唷!
以上,是我們課程的講師助教群,特別精心挑選過的一些範例,非堂適合初學者或入門者,可以從初學到進階作為練習使用!
課程進行方式
-
每次三小時,講課加上現場操作 (現場有助教輔導)
-
會幫大家分小組,每個小組會有助教擔任 mentor
-
每堂課後都有 Office Time,讓大家可以現場找 mentor 請益
-
每次都有小組回家作業或專案,我們希望大家不只能來上課,還能交到許多可以一起合作的蟲友們。
-
所以,當您報名之後,我們會針對大家想爬行的網站,進行分組。並在此同時,就會有小組 mentor 與您聯繫,讓您可以加入一些小組對話群組,並熟悉界面與論壇的使用!
上課前,的課前作業 ...
-
如果您不熟悉 Python 的話 ...
-
可以從這裡開始:https://www.codecademy.com/en/tracks/python 動手學 Python
-
或是,習慣看影片學習的朋友,也可以從這邊開始:https://www.coursera.org/course/interactivepython1
-
或是,另一門 Python 的基礎課程(課程 final project 是自己寫爬蟲 + 網站搜尋引擎) https://www.udacity.com/course/intro-to-computer-science--cs101
-
-
如果您對 HTML 和 CSS 沒有基礎概念的話 ...
-
可以從這裡開始:http://www.codecademy.com/en/tracks/web 動手學 HTML & CSS
-
或是習慣看影片學習的朋友,也可以從這邊開始:https://www.udacity.com/course/intro-to-html-and-css--ud304
-

課程進度與時程安排
-
Week 1 (10/3)
-
爬蟲爬什麼?
-
爬完之後會產出什麼呢?
-
The Secret of Web
-
網頁入何出現在你眼前的?
-
如何觀看網頁的各種 connections?
-
你想抓的 data 在頁面上的哪裡?
-
你想抓的 data 在哪一個 connection 中?
-
什麼是 Ajax 網頁?
-
-
標出你想要的 data
-
CSS Selector
-
XPath Selector
-
-
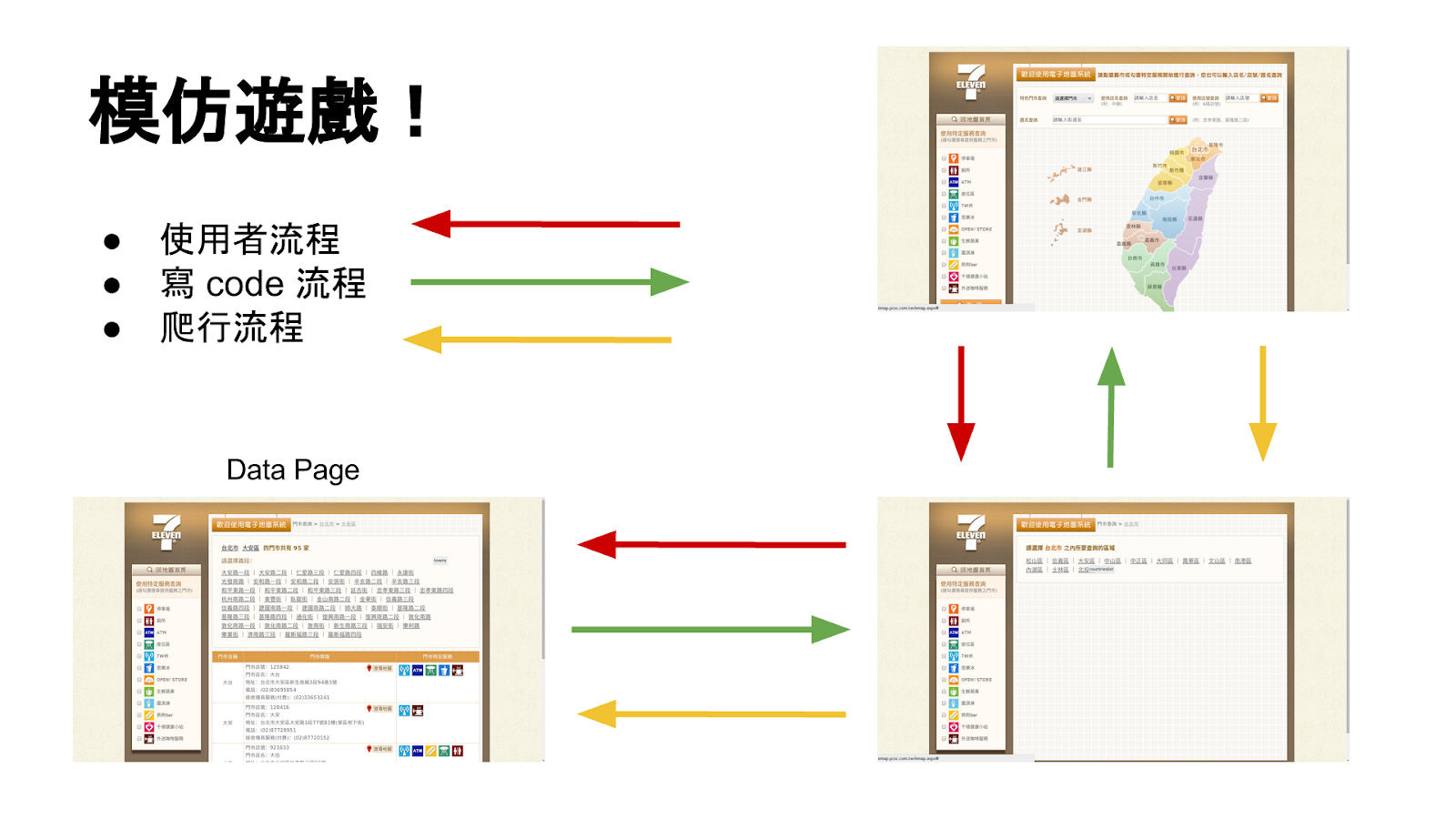
基本的爬蟲架構:connector + parser + database
-
如何用 Python 寫出最簡單的爬蟲
-
-
Week 2 (10/17)
-
如何用 Python 模仿瀏覽器的行為?
-
Connection Skills (with Python) :
-
GET / POST
-
URLencode / URLdecode (破解中文網址的祕密)
-
header & cookie
-
如何突破使用 cookie 阻擋的網站 (如ptt 18 禁...等等)
-
-
Parsing Skills (with Python):
-
css selector
-
xpath selector
-
json
-
xml
-
-
Data Storage
-
如何將資料輸出成 CSV
-
如何將資料存入 SQLite
-
-
-
Week 3 (10/17)
-
Connection Skills (with Python):
-
如何學習與使用第三方 API ?
-
教學範例:Facebook Graph API
-
API 簡介
-
node & edge
-
metadata
-
fields & connections
-
-
實做範例:
-
當個自己的小小徵信社:尋找一下,近三個月內最喜歡按你贊的人是誰?
-
如何自動在 FB 上 post 文章 ?
-
如何自動幫朋友的文章按贊 ?狂贊士 ?
-
-
-
其他常見 (用) 的第三方 API 有哪些 ?
-
-
Parsing Skills (with Python):
-
Regular Expression 簡介
-
如何用 RegEx 抽取非結構化資料 (非HTML/XML/JSON)
-
如何抓取網頁中的電話號碼?地址?
-
-
會用到的套件
基本上會碰到這幾個 requests,urllib,urllib2,BeautifulSoup,pyquery,re...
課前說明會
此外,為了讓大家可以在上課之前,更了解我們的課程。
讓大家可以做好更充沛的課前預習,以便能在學習時發揮最大效益!
我們特別準備了一場課前說明會,讓大家可以到現場來提問唷!
http://datasci.kktix.cc/events/pycrawlerinfo201509
如果您是還在猶豫是否要報名的朋友,那就更應該來參加我們準備的課前說明會了!
相信,一定可以讓您覺得,這是一次非常值得投資的學習與體驗!
而且,如果您想用三人團報方案,但是苦於找不到夥伴一起團報的話,那就更應該參加本次的說明會了!說不定就可以在現場遇到一起團報的夥伴囉!
http://data-sci.info/forums/topic/pycrawler-101-糾團範例缺一-or-缺二/
課外砍站活動: A Crawler A Day
為了讓上過木刻思開的爬蟲課的學員們 (目前開過 Python & R 的課),能有更多練習的機會。
我們之前特別企劃了一個爬蟲的練習活動:A Crawler A Day
http://data-sci.info/a-crawler-a-day/
讓大家可以在學習之餘,也能有更多練習和玩耍的機會!
其實,寫爬蟲是一件非常有趣的事情,希望大家都能夠發揮柯南的精神,享受探索網站的樂趣!
報名課程附有發票
所以,請您在填寫報名表時,務必註明所需要的發票種類,如果需要三聯發票,也請註明統一編號!
退票機制
課程前11天以上退票,kktix 手續費10%(kktix受理退票事宜)。
課程前10天內退票,公司處理退票手續費20%。
團報優惠
由於,課程會分組,所以我們特別提供三人報名的優惠,讓大家可以在報名時就先揪好小組組員!
課程木刻思之友優惠
此外,若您曾經上過木刻思開設過的其他爬蟲課程 (RCrawler, PyCrawler.. ) 等等
想請購優惠票,也請您來信至
course@agilearning.io
並使用信件 Title:
[PyCrawler 報名] 優惠票請購
並請在信中註明一下,之前曾經上過的課程!
(我們將提供您優惠票的 Promotion Code)
歡迎企業包班上課
另外,如果您的企業有超過 20 人想報名上課的話。
也歡迎來信至 course@agilearning.io
並使用信件 Title:
[PyCrawler 報名] 企業包班申請
我們也非常歡迎企業包班上課唷!
PyCrawler 課程輪開週期
由於,公司開課人力 (講師與助教) 有限。
本次的 PyCrawler 初階課程,將會以三到四個月輪開一次的週期,一年三次左右的次數輪開。
所以,錯過這次,下次最快能上到同一堂課的機會,可能是三四個月 (或更久) 以後囉!
在中間的時間中,我們會開設更多的進階課程,以及延伸學習課程!
希望能讓學員們,在取得資料資後,能夠做更多的應用,視覺化,與分析!













